Informações importantes – Em prol do Outubro Rosa
- Quando um nódulo maligno na mama é diagnosticado com menos de 1 cm de diâmetro, as chances de cura são de 95%!
- A incidência do Câncer de Mama cresce principalmente após os 40 anos.
- A prevenção é o melhor caminho!
Como é mês de Outubro é o mês da conscientização do Câncer de Mama, acreditamos que seria importante se o tema viesse a tona de alguma forma em um dos nossos posts, dessa forma, decidimos considerar um banco com essa temática para a análise de dados. Aqui vamos observar o banco de dados chamado Breast Cancer Wisconsin, trata-se de um banco famoso que pode ser encontrado no Kaggle, por exemplo. O desafio proposto é tentar prever a partir de variáveis se o nódulo é benigno ou maligno. Ou seja, um problema de classificação. Nosso foco principal nesse post é mostrar algumas ideias que devem ser levadas em consideração ao invés de ajustar o modelo.
Dados Desbalanceados
Quando estamos trabalhando com problemas de classificação umas das primeiras características que devemos nos atentar é a proporção das categorias presentes na variável resposta. Quando as classes são balanceadas, ou seja, estão mais ou menos em mesma quantidade, os modelos costumam trabalhar bem melhor. No entanto, quando temos desbalanceamentos, por exemplo quando a classe de interesse representa apenas 10% ou até menos, mais cuidados devem ser tomados e o conhecimento do negócio analisado deve ser considerado. O problema ocorre porque mesmo se o modelo categorizar todas as observações na classe majoritária, a proporção de acerto ainda é 90%. No caso do nosso banco de dados o desbalanceamento é “tranquilo”.

Seleção de Variáveis
As variáveis que serão utilizadas para explicar o nosso modelo também devem ser observadas, provalvemente não é interessante adicionar todas as variáveis no seu modelo e essa prática também pode auxiliar a gastar menos memória durante o ajuste. Algumas características que podem ser observadas são:
- Identificador: é comum que exista uma variável no banco responsável por identificar cada indivíduo. Se cada indivíduo tem um valor único, não é interessante adicioná-la ao modelo;
- Sem variação: há também o caso contrário, se uma variável no banco recebe o mesmo valor para todos os indivíduos, não será útil no modelo final;
- Multicolinearidade: Existe a possibilidade também que duas ou mais variáveis explicativas sejam correlacionadas, com isso, é melhor manter apenas uma delas para a explicação;
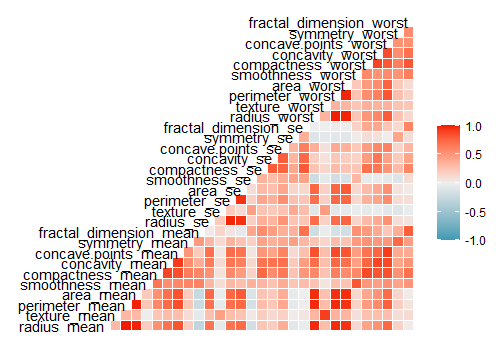
No banco que escolhemos trabalhar identificamos que a variável Id corresponde ao Identificador comentado, além disso, as variáveis que relacionadas a área, diâmetro e perímetro do nódulo são extremamente correlacionadas, além da retirada de outros casos que mostraram correlação significativa. Ao final decidimos continuar com as variáveis: “texture_mean”, “area_mean”, “smoothness_mean”, “concavity_mean”, “symmetry_mean”, “fractal_dimension_mean”, “texture_se”, “area_se”, “smoothness_se”, “concavity_se” “symmetry_se”, “fractal_dimension_se”. Na figura abaixo pode-se observar a matriz com as correlações.
Valores Atípicos
Entre a faxina realizada nos bancos de dados, provavelmente você encontrará valores inesperados, que necessitarão ser avaliados dada a possibilidade de serem erros. Como por exemplo:
- Ouliers: Valores que são extremamente distantes das demais observações. Muito se discute sobre a retirada ou não dessas observações, mas isso deve ocorrer apenas quando é comprovada a ocorrência de algum erro. Além disso, deve-se ter em mente que a presença de outliers pode influenciar ou não o resultado do modelo escolhido, como é o caso da Regressão Logística;
- Valores Influentes: Valores que apresentam influencia maior que esperada no modelo ajustado.
- Valores Faltantes: Os famosos NA podem ocorrer por diversos motivos. Algumas técnicas não podem ser usadas nessa situação. Mas ainda é possível completar as observações faltantes a partir das outras informações disponíveis, esse ato é chamado de imputação.
Outras características
Há ainda outras características que podemos avaliar e trabalhar, como por exemplo:
- Muitas categorias: Uma variável categórica pode apresentar muitas categorias, pode fazer sentido agrupar as menos frequentes em uma categoria única chamada “Outras”…
- Padronização: Muitas vezes a diferença entre as escalas das variáveis pode ser muito destoante, esse detalhe também pode afetar o desempenho de alguns modelos, nesses casos é válido fazer a padronização ou normalização.
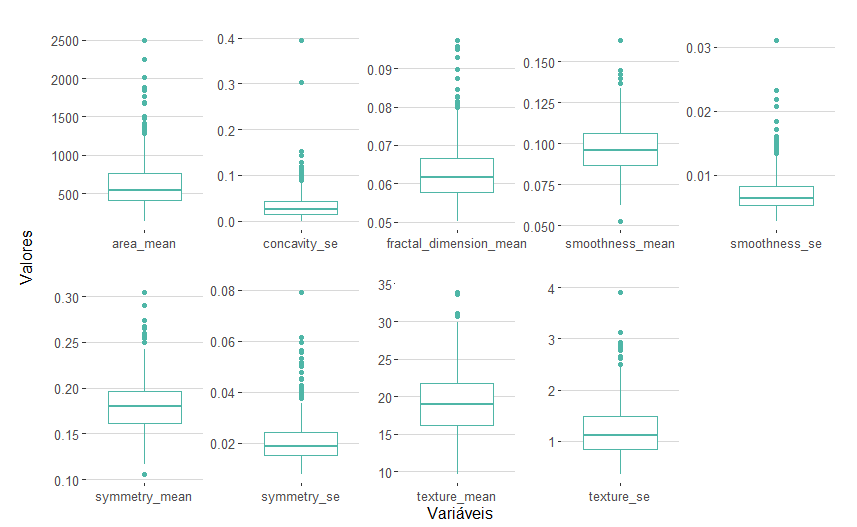
A partir dos boxplots das variáveis escolhidas para ir para o modelo, vemos: assimetria, presença de outliers e escalas totalmente diferentes no banco de dados. Além disso, também sabemos previamente que não há valores faltantes.
Divisão do Banco de Dados
Antes de treinar nosso modelo, um passo crucial é separar o banco de dados entre Treino e Teste, a primeira parcela dos dados serão utilizados para o ajuste do modelo e o restante para testar se o modelo gerado consegue generalizar e se sair bem com novos dados. Algumas proporções comumente utilizadas são 80/20 e 75/25.
Além disso, alguns modelos funcionam com hiperparâmetros, isto é, valores que são usados durante a modelagem e com isso devem ser definidos anteriormente. Para otimizá-los, ou no jargão da área, tuná-los, técnicas de reamostragem são utilizadas.
Métricas
Para avaliar o desempenho de um Modelo de Classificação, um objeto que nos ajuda muito é a matriz de confusão, a partir dela podemos verificar como as classificações se comportaram. O exemplo utilizado a seguir foi retirado desse artigo.
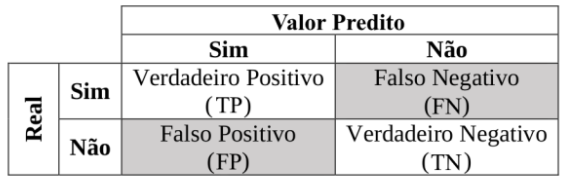
Ao visualizar a matriz de confusão fica mais fácil de entender as métricas que podem ser utilizadas na validação do nosso modelo:
- Acurácia: Proporção de classificações corretas entre todas as observações, equivalente à (TP + TN)/Valor Total. Essa métrica é mais interessante quando as classes estão balanceadas;
- Sensibilidade ou Recall: Proporção de classificações corretas, entre os valores que são realmente Positivos. Calculado por TP/(TP + FN).
- Especificidade: Proporção de classificações corretas, entre os valores que são realmente Negativos. Calculado por TP/(TP + FN).
- VPN (Valor Predito Negativo): Proporção de classificações corretas, entre os valores que receberam classificação Positiva. Calculado por TN/(TN + FN)
- Precisão ou VPP: Proporção de classificações corretas, entre os valores que receberam classificação Negativa. Calculado por TP/(TP + FP)
As 4 últimas métricas podem ser mais interessantes quando os dados que você estiver trabalhando foram desbalanceados, mas a escolha ainda vai depender do resultado que você precisa, por exemplo se é mais importante acertar os valores Positivos ou os valores Negativos. Em caso de diagnósticos de doenças, como é a temática do banco que escolhemos, geralmente é mais importante ter certeza que todas as observações que indicam a presença da doença sejam detectadas, mesmo que isso resulte em um quantidade considerável de falsos negativos.
Referências
- https://www.tmwr.org/pre-proc-table.html

