
O spotifyr é um pacote do R que funciona como um wrapper da Web API do Spotify, isto é, suas funções permitem que algumas informações sobre músicas, artistas e até o que outros usuários escutam sejam coletadas. Nesse post iremos dar instruções sobre como utilizar o pacote, mostrar algumas funções interessantes e também exemplificar utilizando músicas escolhidas pelos membros da empresa júnior.
Instalação & autorizações
Assim como em muitos pacotes do R, é necessário realizar a sua instalação. O mesmo já está presente no CRAN, então é possível fazer instalá-lo e em seguida carregá-lo por meio dos comandos:
install.packages('spotifyr');
library(spotifyr)
Além de instalar o pacote, é necessário obter as chaves e senhas de acesso da Web API como desenvolvedor. Elas podem ser facilmente obtidas a partir desse link: https://developer.spotify.com/dashboard/login . Para obté-las, você deve realizar o login com sua conta do Spotify, a partir disso, você será encaminhado para a seção de Dashboard e deverá clicar em “Create an app”.

Com isso, você deve escolher um nome, descrição e seguir clicando em “Create”.

Na nova janela aberta, estão as informações necessárias para autenticar o nosso acesso enquanto estivermos utilizando o R: o número de Client ID e Client Secret mostrado após clicar em “Open”.

Mas antes de voltar para o R, é necessário fazer uma alteração nas configurações. Em “edit settings” é preciso adicionar uma URL para auxiliar na autenticação de algumas funções, principalmente funções que acessam informações específicas da sua conta. Não é necessário ter uma URL própria, um dos autores do pacote indica utilizar a http://localhost:1410/. Após adicionar o link em “Redirect URIs”, não se esqueça de clicar no botão ADD ao lado.

Com as chaves em mãos, podemos voltar ao R. Agora, para adicionar nossas credenciais, é necessário executar os comandos mostra a seguir, e com isso, você terá liberdade para utilizar os dados da API!
Sys.setenv(SPOTIFY_CLIENT_ID = 'xxxxxxxxxxxxxxxxxxxxx')
Sys.setenv(SPOTIFY_CLIENT_SECRET = 'xxxxxxxxxxxxxxxxxxxxx')
access_token <- get_spotify_access_token()
Antes de conferir as funções do pacote, acredito que seja interessante comentar que seu acesso será por padrão os dados da sua conta, para acessar as informações de outras pessoas é necessário seus respectivos IDs. Além disso, o Spotify possui variáveis para caracterizar todas as músicas e podem ser extremamente úteis para a sua análise. Trouxe o significado de algumas delas:
Danceability: Variável numérica que recebe valores entre 0 e 1. Descreve o quanto uma música é considerada “dançável” a partir de uma combinação de aspectos como ritmo, estabilidade e quantidade de batidas.
Energy: Indica um percentual de intensidade e atividade da música. Seus valores variam entre 0 e 1. Uma música com alto valor dessa variável provavelmente será rápida e até considerada “barulhenta”.
Valence: Também possui valores que variam entre 0 e 1. Expressa a positividade contida na música, ou seja, músicas alegres e eufóricas terão valores altos para essa variável, enquanto músicas mais tristes e raivosas possuirão valores baixos.
Speechiness: Detecta a proporção da música em que palavras são ditas na faixa. Também varia entre 0 e 1.
Tempo: Tempo é um conceito na teoria da música que representa a velocidade ou ritmo da música, nessa variável estão representados valores da duração média de batidas por minuto (BPM) da música.
Conhecendo o spotifyr
Após todas as considerações dadas, é possível prosseguir com os comandos no R. Lembrando que as funções serão usadas em conjunto com outras funções de manipulação e visualização de dados, para evitar prolongações e focar nas funções do spotifyr não iremos entrar em detalhes. Qualquer dúvida pode ser deixada nos comentários!
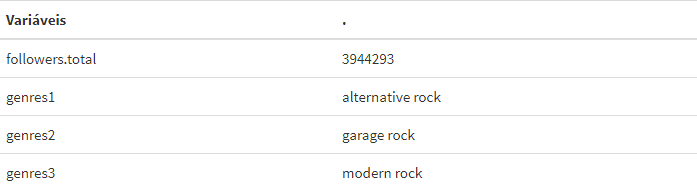
A primeira função que explicarei é a get_artist(), com ela é possível extrair algumas informações básicas sobre algum artista, por exemplo número de seguidores na plataforma, gêneros atribuídos e popularidade. Para utilizá-la é preciso adicionar como argumento o ID do artista, o resultado gerado fica no formato de lista.
get_artist("0epOFNiUfyON9EYx7Tpr6V") %>%
unlist() %>% .[2:5] %>% as.data.frame() %>% # Transformando de lista para um data-frame;
rownames_to_column(var = "Variáveis") %>%
kbl() %>% kable_styling()
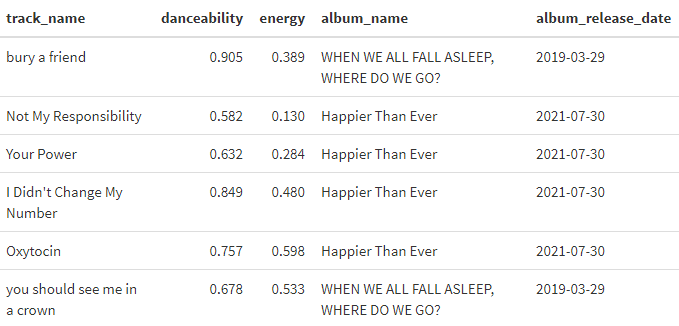
Outra função interessante é a get_artist_audio_features(), ela nos retorna um data-frame com informações sobre todas as músicas do artista escolhido. Entre as informações estão as variáveis que o próprio spotify determina e foram comentadas anteriormente. Para sua utilização é necessário utilizar o nome do artista como argumento.
get_artist_audio_features("Billie Eilish") %>%
select(track_name, danceability, energy, album_name, album_release_date) %>%
sample_n(6) %>%
kbl() %>% kable_styling()
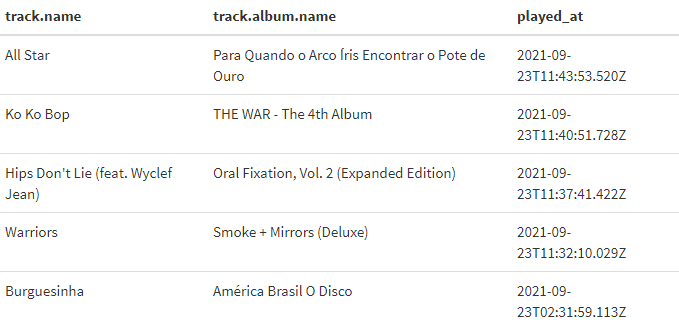
Com a função get_my_recently_played() você consegue extrair as últimas músicas que foram tocadas na sua conta. Por padrão, a função retorna 20 músicas, mas você pode configurar até o limite máximo, igual a 100 músicas.
get_my_recently_played(limit = 5) %>%
select(track.name, track.album.name, played_at) %>%
kbl() %>% kable_styling()
Já a função get_my_top_artists_or_tracks() retorna um data-frame com as informações dos artistas ou músicas que você mais escuta. Entre os argumentos utilizados com a função é possível escolher: type, que recebe “artists” ou “tracks”, limit, que é o número de observações que serão coletadas e time_range, que recebe “long_term” para que a escolha considere todo o período que você possui sua conta, “medium_term” (opção defaulf) para a escolha dos favoritos nos últimos 6 meses e “short_term” para as últimas 4 semanas.
get_my_top_artists_or_tracks(type = "artists", limit = 5) %>%
select(name, genres) %>%
kbl() %>% kable_styling()

Um detalhe curioso para mim é a diversidade de gêneros musicais, são incluídos características que eu sequer considerava como um gênero. No entanto, essa é uma estratégia bem interessante dada a quantidade gigantesca de artistas e músicas presentes na plataforma, deixar os gêneros bem específicos facilita para definir grupos menores e semelhantes.
get_my_top_artists_or_tracks(type = "tracks", limit = 5) %>%
select(name, album.name, album.release_date) %>%
kbl() %>% kable_styling()

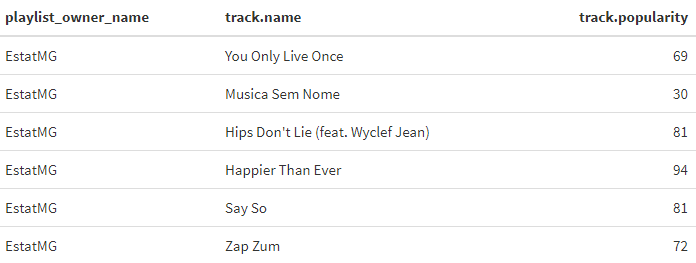
Além disso, também é possível extrair as músicas e outras informações de uma playlist específica do Spotify. A função que realiza essa tarefa é a get_playlist_audio_features(). Para utilizá-la é preciso passar como argumentos o código da playlist e o seu nome. Para conseguir o código de uma playlist basta copiar os últimos dígitos da URL da mesma.

get_playlist_audio_features("Integrantes - 2021", "7eZreLsVfaNRFB5W0pZQHN") %>%
select(playlist_owner_name, track.name, track.popularity) %>%
head() %>% kbl() %>% kable_styling()
E para finalizar essa seção, achei interessante as funções get_recommendations() e get_related_artists(). Ambas ajudam a encontrar recomendações, a primeira com músicas de um gênero definido e a segunda com artistas parecidos com outro artista escolhido.
Hora dos Exemplos
Primeiramente, eu achei interessante que as músicas utilizadas representassem bem a EstatMG, por isso, pedi a todos os integrantes que me enviassem 3 músicas e elas foram utilizadas nos resultados apresentados! Se tiver interesse em escutar essas músicas aqui está o link: https://open.spotify.com/playlist/7eZreLsVfaNRFB5W0pZQHN
OBS: O script completo com os comandos utilizados a seguir está disponível no nosso Github: https://github.com/EstatMG/analises_spotify
Além disso, outros pacotes que foram utilizados nas visualizações foram:
library(tidyverse)
library(wordcloud2)
library(gghighlight)
library(lubridate)
library(patchwork)
Para a extração dos dados, o código mostrado a seguir foi utilizado. Obseve que após especificar a playlist necessária, a variável que possui informações sobre os artistas foi trabalhada para sair do formato de lista (uma estrutura que faz muito sentido quando as músicas são produto da contribuição de vários artista), e em seguida mantive apenas o artista principal da música para facilitar a análise. Dada a quantidade de variáveis contida no banco, preferi selecionar apenas algumas delas. E para complementar o banco, obtive os gêneros do artista de cada música, bem como a popularidade a partir da função get_artist().
dados <- get_playlist_audio_features("Integrantes - 2021", "7eZreLsVfaNRFB5W0pZQHN") %>%
unnest(track.artists) %>% # Variável a principío como lista;
distinct(track.id, .keep_all = TRUE) %>%
select(added_at, track.id, track.name, artist.id = id, artist.name = name,
track.album.name, track.album.release_date, track.album.release_date_precision,
track.popularity, danceability, energy, loudness, speechiness, acousticness,
instrumentalness, liveness, valence, tempo) %>%
rowwise() %>%
mutate(genres = str_flatten(get_artist(artist.id)$genres, collapse = ","),
artist.popularity = get_artist(artist.id)$popularity)
A primeira visualização que eu pensei seria identificar os artistas mais frequente entre o banco de dados, no entanto, apenas dois artistas principais foram repetidos: Engenheiros do Hawaii com 3 observações (de um mesmo integrante, inclusive) e o Silva com duas músicas.
Prosseguindo para outra análise interessante, podemos observar quais são os gêneros mais frequentes entre as músicas escolhidas. A primeira tentiva tem um apelo visual e é uma nuvem de palavras, a partir dela já é possível identificar que Rock Brasileiro e Pop/Pop Dançante estão bastante presentes.
dados %>% separate_rows(genres, sep = ",") %>%
group_by(genres) %>% count() %>%
wordcloud2(minSize = 5)

Filtrando ainda mais as observações podemos plotar também um gráfico de barras. Nesse caso optei por observar a frequência relativa, dividindo as frequências pelo número total de músicas no nosso repertório, lembrando que todas as músicas possuem mais de um gênero, por isso devemos tomar esse cuidado. Com isso, observamos que um quarto das músicas possui pelo menos um toque de pop e um quinto delas tem traços de MPB.
dados %>% separate_rows(genres, sep = ",") %>%
group_by(genres) %>% count() %>% ungroup() %>%
slice_max(order_by = n, n = 10) %>%
mutate(prop = n/nrow(dados),
genres = fct_reorder(as.factor(genres), prop)) %>%
ggplot(aes(y = genres, x = prop)) +
geom_col(fill = "#4fb6a7") + labs(y = "", x = "Proporção")

Outra dúvida que passou pela minha cabeça durante as análises foi: será que os integrantes das EstatMG preferem músicas da última década ou são fãs das mais antigas? Podemos conferir isso com o próximo histograma, onde a prevalência está em músicas do século XXI. E a título de curiosidade, a música mais antiga é “Like a Rolling Stone – Bob Dylan” de 1965.
dados %>%
mutate(track.album.release_date = str_sub(track.album.release_date, end = 4) %>%
as.numeric()) %>%
ggplot(aes(track.album.release_date)) +
geom_histogram(color = "white", fill = "#652177", bins = 15) +
labs(y = "Contagem", x = "")

Devido a quantidade de variáveis numéricas presentes no banco, apenas algumas foram selecionadas nessa etapa da visualização, mais a título de ilustração. Em geral, as variáveis se mostraram bem dispersas, apenas observa-se assimetrias acentuadas nas variáveis Instrumentalnees e Speechiness.
dados %>% select(-ends_with("popularity"), -liveness) %>%
pivot_longer(cols = where(is.numeric), names_to = "Variáveis", values_to = "Valores") %>%
ggplot(aes(x = `Variáveis`, y = Valores)) +
geom_boxplot(color = "#4FB6A7") + geom_jitter(color = "#4FB6A7", title = NA) +
facet_wrap(vars(`Variáveis`), scales = "free", nrow = 2)

E com tantas variáveis numérias, porque não avaliar o relacionamento entre pares das mesmas? Primeiro, escolhi avaliar Energia x Dançabilidade, a princípio as variáveis não aparentam uma correlação forte. Além disso, imaginei que fosse interessante também destacar as músicas que possuem os maiores valores, por exemplo, com os menores valores de Dançabilidade temos Hocus Pocus – Focus e Too Much Is Not Enough – Graveyard enquanto a mais dançante é a versão Mega da Dance Monket – Dj Nattan. E ainda, temos como música mais energética Na Le – Omiki e o oposto é visto para Happiness is a Butterfly – Lana Del Rey.
g1 <- dados %>%
mutate(label = paste(track.name, artist.name, sep = " - ")) %>%
ggplot(aes(danceability, energy)) +
geom_point()
g2 <- dados %>%
mutate(label = paste(track.name, artist.name, sep = " - ")) %>%
ggplot(aes(danceability, energy, color = label)) +
geom_point() +
gghighlight(danceability < 0.3 | danceability > 0.85 | energy < 0.15 | energy > 0.97,
label_key = label)
g1 + g2

Ao avaliar o gráfico de Valência x Tempo, também não é possível perceber uma correlação específica. E entre os destaques podemos dizer que as músicas O – Coldplay, Flares – The Script e Snow Crystal – Babalos possuem os menores valores de Valence, ou seja, são músicas menos positivas, enquanto You Only Live Once – The Strokes, Mina do Condimínio – Seu Jorge e Deixa Acontecer – Grupo Revelação aparentam possuir mais possitividade, em relação a letra e ao ritmo. E novamente Happiness is a Butterfly – Lana Del Rey se destaca como uma música lenta, por ter baixo valor de Tempo.
g1 <- dados %>%
mutate(label = paste(track.name, artist.name, sep = " - ")) %>%
ggplot(aes(valence, tempo)) +
geom_point()
g2 <- dados %>%
mutate(label = paste(track.name, artist.name, sep = " - ")) %>%
ggplot(aes(valence, tempo, color = label)) +
geom_point() +
gghighlight(valence < 0.07 | valence > 0.95 | tempo > 185 | tempo < 75,
label_key = label)
g1 + g2

Eu irei parar com as visualizações por aqui, mas existem ainda muitas outras formas de analisar e variáveis que podem ser analisados: Os títulos das músicas refletem algum sentimento específico? É possível agrupar as músicas de alguma forma? Ou a data em que as músicas foram adicionadas na playlists indicam algum alteração no seu gosto? É um mundo de possibilidades!

